Warning: package 'rpart' was built under R version 4.2.3
Attaching package: 'rpart'
The following object is masked from 'package:dials':
prune
library(ranger)
Warning: package 'ranger' was built under R version 4.2.3
library(glmnet)
Warning: package 'glmnet' was built under R version 4.2.3
Loading required package: Matrix
Attaching package: 'Matrix'
The following objects are masked from 'package:tidyr':
expand, pack, unpack
Loaded glmnet 4.1-7
library(rpart.plot)
Warning: package 'rpart.plot' was built under R version 4.2.3
library(vip)
Warning: package 'vip' was built under R version 4.2.3
Attaching package: 'vip'
The following object is masked from 'package:utils':
vi
Rows: 220 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): prod_type, prod_process, source
dbl (2): n_hens, n_eggs
date (1): observed_month
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 96 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): source
dbl (2): percent_hens, percent_eggs
date (1): observed_month
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Data Exploration and Cleaning
# getting an idea of the dimensions and classes of dataglimpse(egg)
observed_month prod_type prod_process n_hens
Min. :2016-07-31 Length:220 Length:220 Min. : 13500000
1st Qu.:2017-09-30 Class :character Class :character 1st Qu.: 17284500
Median :2018-11-15 Mode :character Mode :character Median : 59939500
Mean :2018-11-14 Mean :110839873
3rd Qu.:2019-12-31 3rd Qu.:125539250
Max. :2021-02-28 Max. :341166000
n_eggs source
Min. :2.981e+08 Length:220
1st Qu.:4.240e+08 Class :character
Median :1.155e+09 Mode :character
Mean :2.607e+09
3rd Qu.:2.963e+09
Max. :8.601e+09
summary(cage)
observed_month percent_hens percent_eggs source
Min. :2007-12-31 Min. : 3.20 Min. : 9.557 Length:96
1st Qu.:2017-05-23 1st Qu.:13.46 1st Qu.:14.521 Class :character
Median :2018-11-15 Median :17.30 Median :16.235 Mode :character
Mean :2018-05-12 Mean :17.95 Mean :17.095
3rd Qu.:2020-02-28 3rd Qu.:23.46 3rd Qu.:19.460
Max. :2021-02-28 Max. :29.20 Max. :24.546
NA's :42
#combine data sets by observed monthfull <-full_join(egg, cage, by="observed_month")
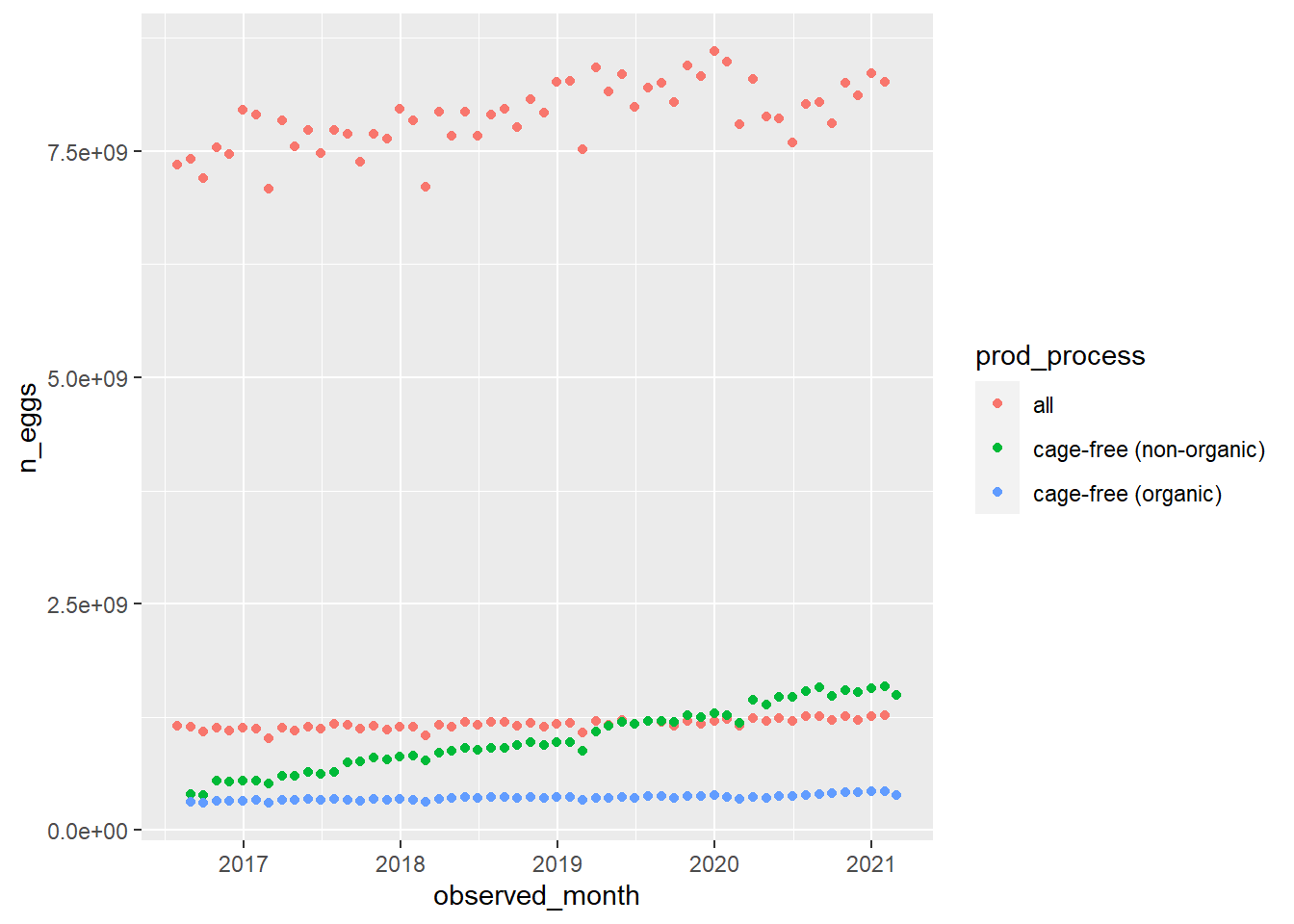
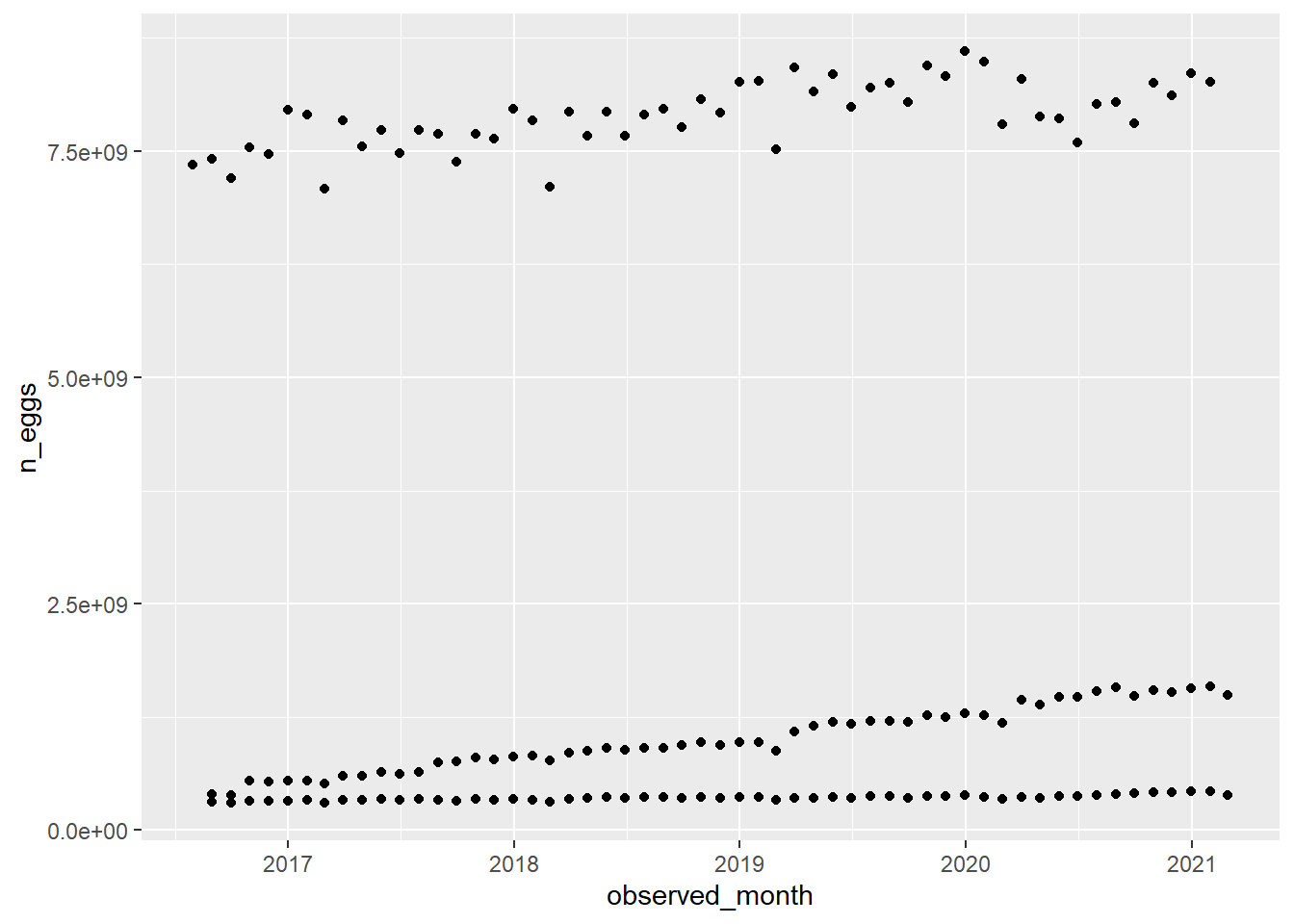
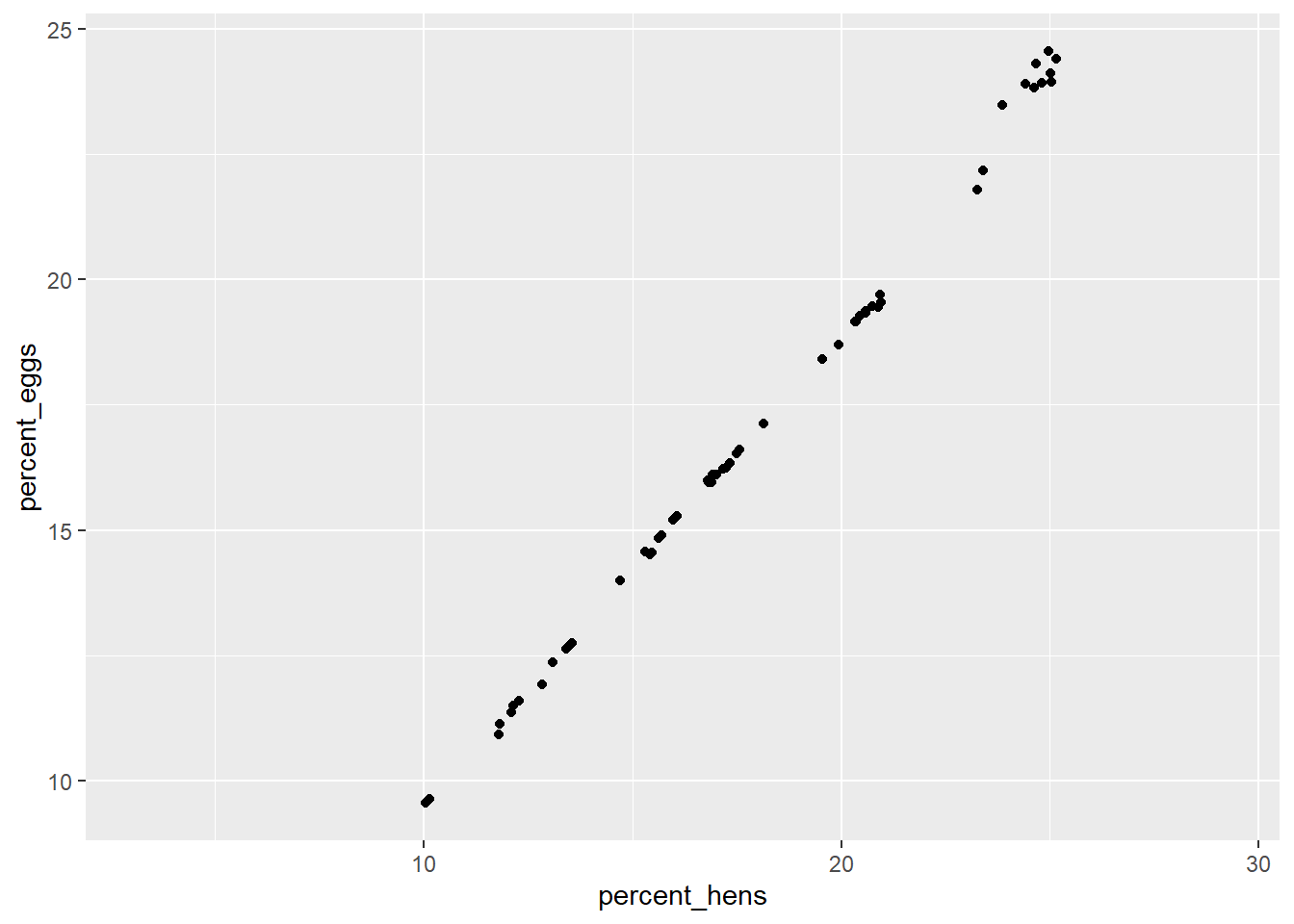
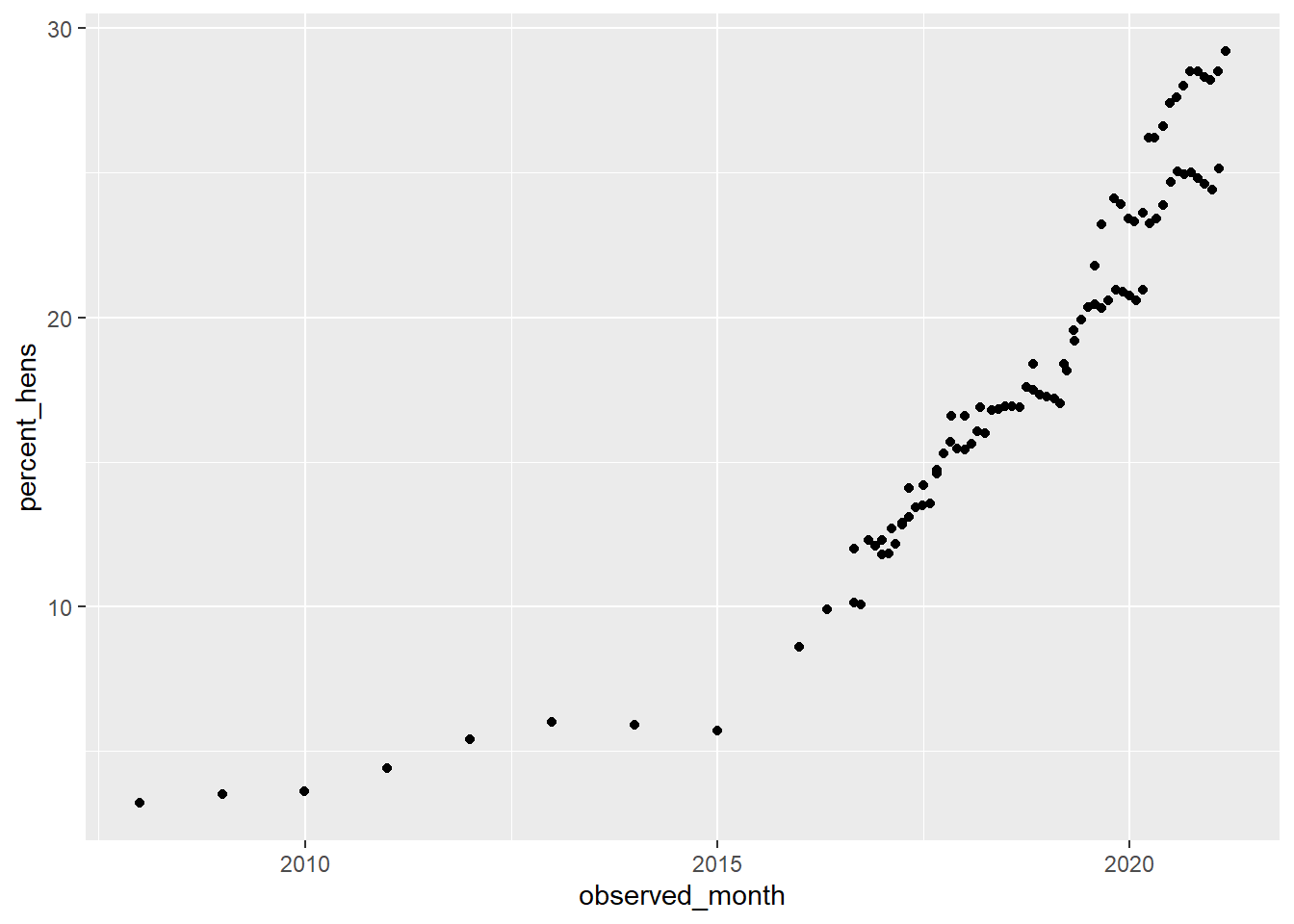
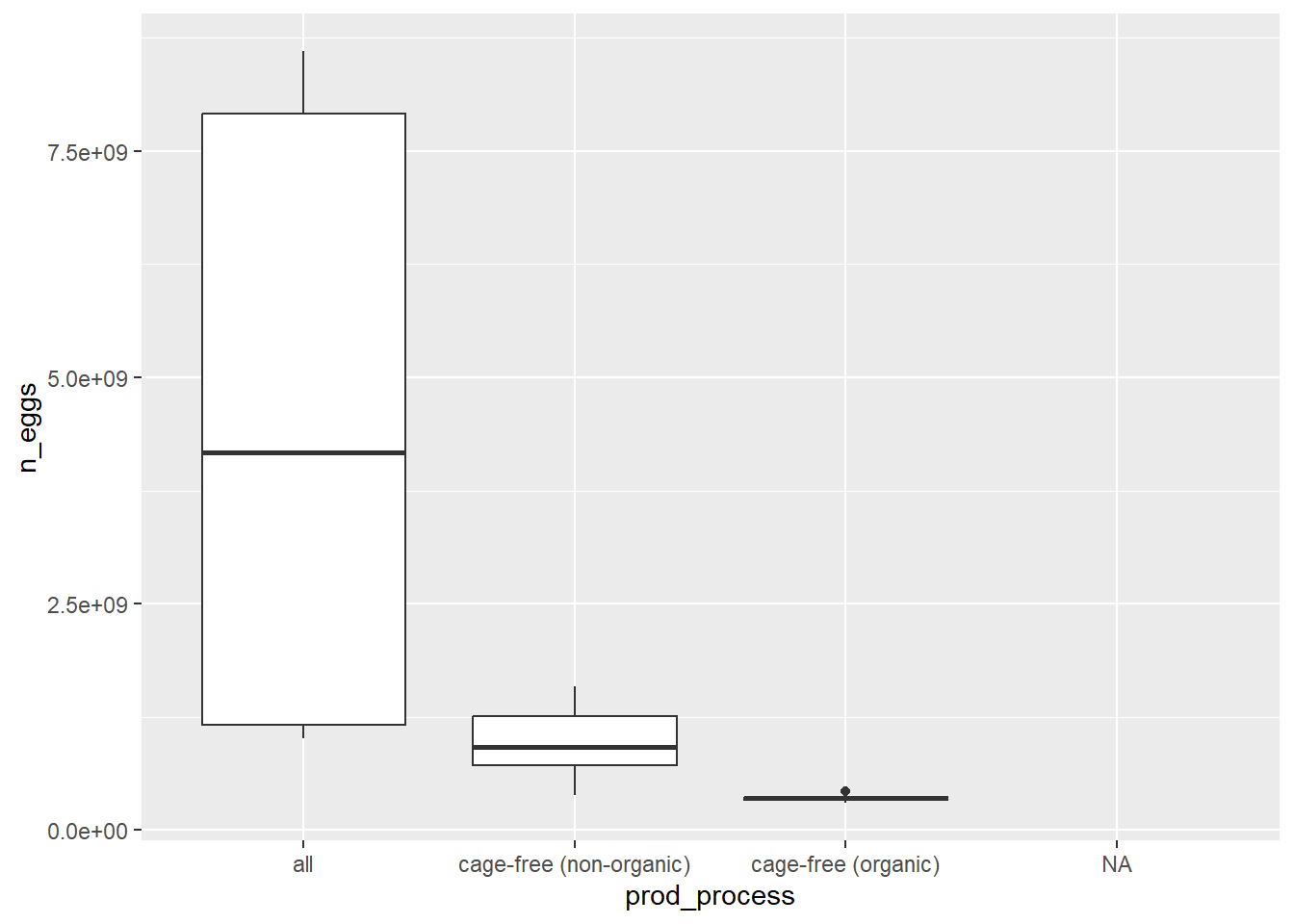
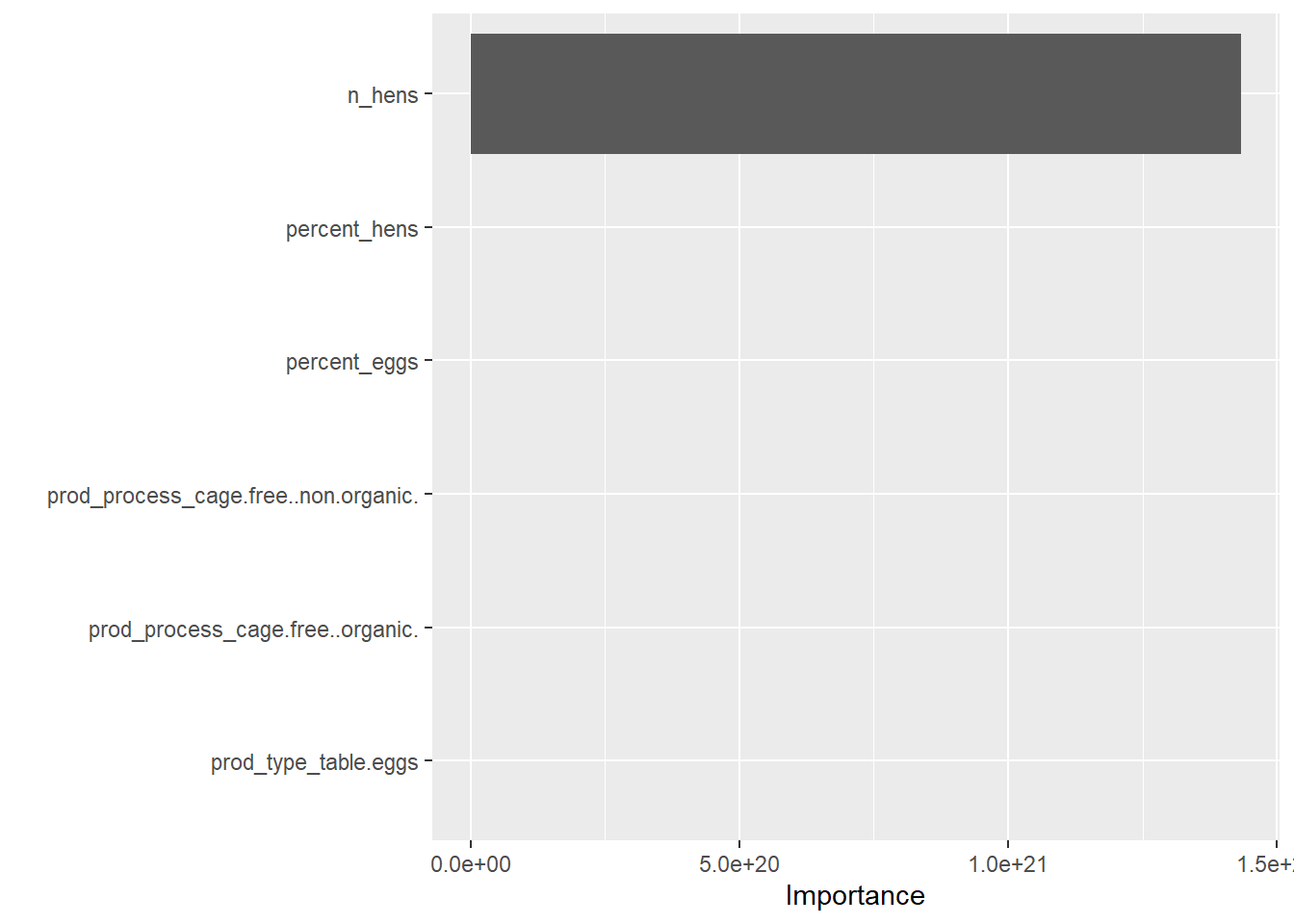
What factors are the most important for determining n_eggs produced? I want to look at how correlated various factors are with total number of eggs produced.
#removing unnecessary columnegg_prod <- full %>%select(-c(source.x,source.y, observed_month))#change prod_type and prod_process to factor variablesegg_prod$prod_process<-as.factor(egg_prod$prod_process)egg_prod$prod_type<-as.factor(egg_prod$prod_type)#drop NAsegg_prod <- egg_prod %>%drop_na()glimpse(egg_prod)
Rows: 216
Columns: 6
$ prod_type <fct> hatching eggs, hatching eggs, hatching eggs, hatching egg…
$ prod_process <fct> all, all, all, all, all, all, all, all, all, all, all, al…
$ n_hens <dbl> 57595000, 57161000, 56857000, 57116000, 57750000, 5799100…
$ n_eggs <dbl> 1142700000, 1093300000, 1126700000, 1096600000, 113290000…
$ percent_hens <dbl> 10.13569, 10.05704, 12.29353, 12.10062, 11.79349, 11.8198…
$ percent_eggs <dbl> 9.634938, 9.557439, 11.602313, 11.372893, 10.922373, 11.1…
#set seedset.seed(123)#data split with 70% in test data and stratified on production processdata_split <-initial_split(egg_prod, prop =7/10, strata = prod_process) #specify train and test datatrain_data <-training(data_split) test_data <-testing(data_split)
# A tibble: 2 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 rmse standard 3122898579. 4 37296457. Preprocessor1_Model1
2 rsq standard NaN 0 NA Preprocessor1_Model1
rf_mod <-rand_forest(mtry =tune(), min_n =tune(), trees =1000) %>%set_engine("ranger", num.threads = cores, importance="impurity") %>%set_mode("regression")#Create workflowrf_workflow <-workflow() %>%add_model(rf_mod) %>%add_recipe(egg_recipe)#Parameters for tuningextract_parameter_set_dials(rf_mod)
Collection of 2 parameters for tuning
identifier type object
mtry mtry nparam[?]
min_n min_n nparam[+]
Model parameters needing finalization:
# Randomly Selected Predictors ('mtry')
See `?dials::finalize` or `?dials::update.parameters` for more information.
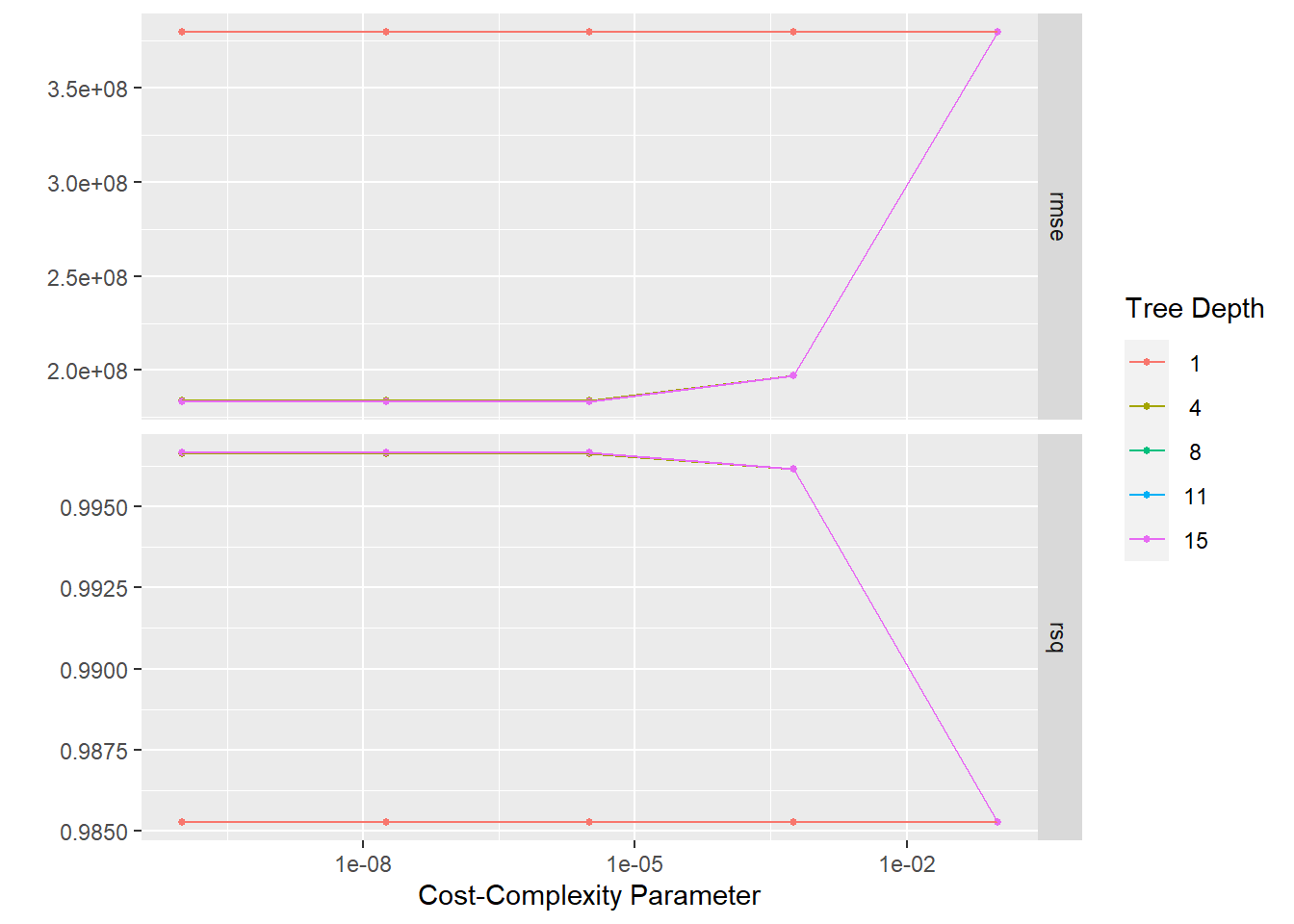
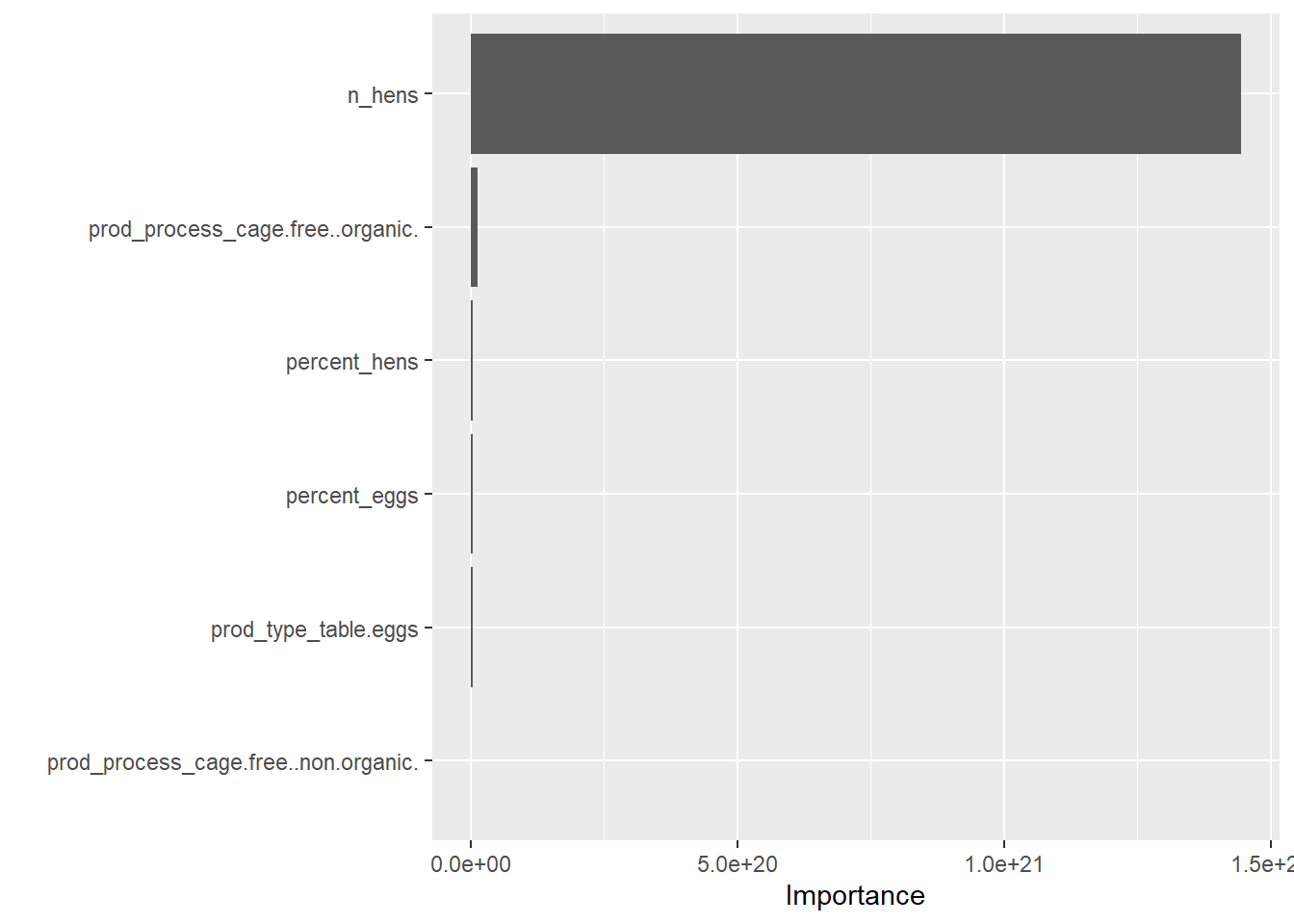
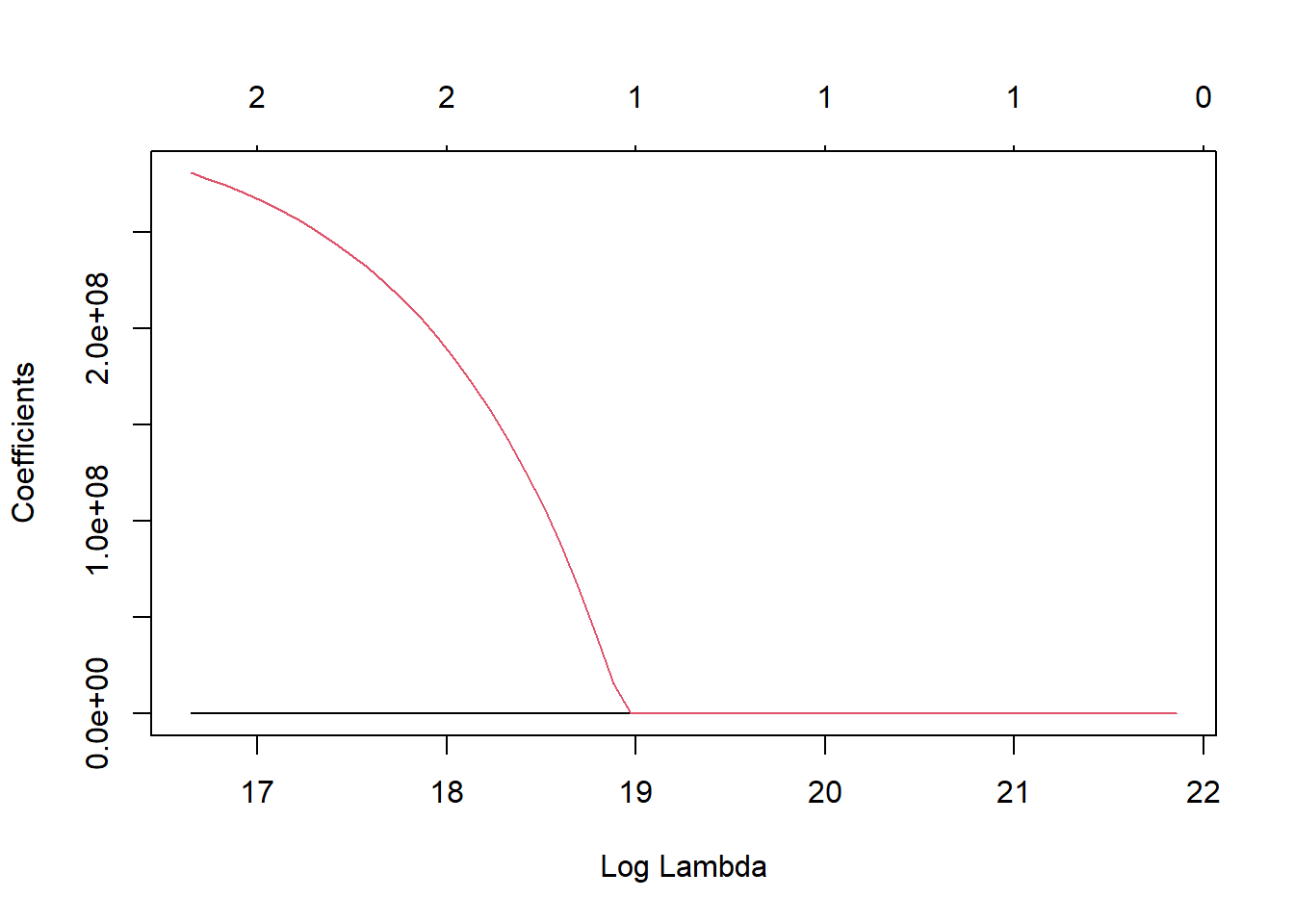
I decided to choose the random forest model because I wanted to have a little more practice with it and because the rmse values for the models were fairly close.