#create the fit from the established workflowflu_fit <- flu_wflow %>%fit(data = train_data)#check prediction to evaluate test datapredict(flu_fit, test_data)
Warning in predict.lm(object, newdata, se.fit, scale = 1, type = if (type == :
prediction from a rank-deficient fit may be misleading
# A tibble: 183 × 1
.pred_class
<fct>
1 No
2 No
3 No
4 No
5 No
6 Yes
7 Yes
8 No
9 No
10 Yes
# … with 173 more rows
Evaluate Performance
#Augment to return probabilities rather than yes or noflu_aug <-augment(flu_fit, test_data)
Warning in predict.lm(object, newdata, se.fit, scale = 1, type = if (type == :
prediction from a rank-deficient fit may be misleading
Warning in predict.lm(object, newdata, se.fit, scale = 1, type = if (type == :
prediction from a rank-deficient fit may be misleading
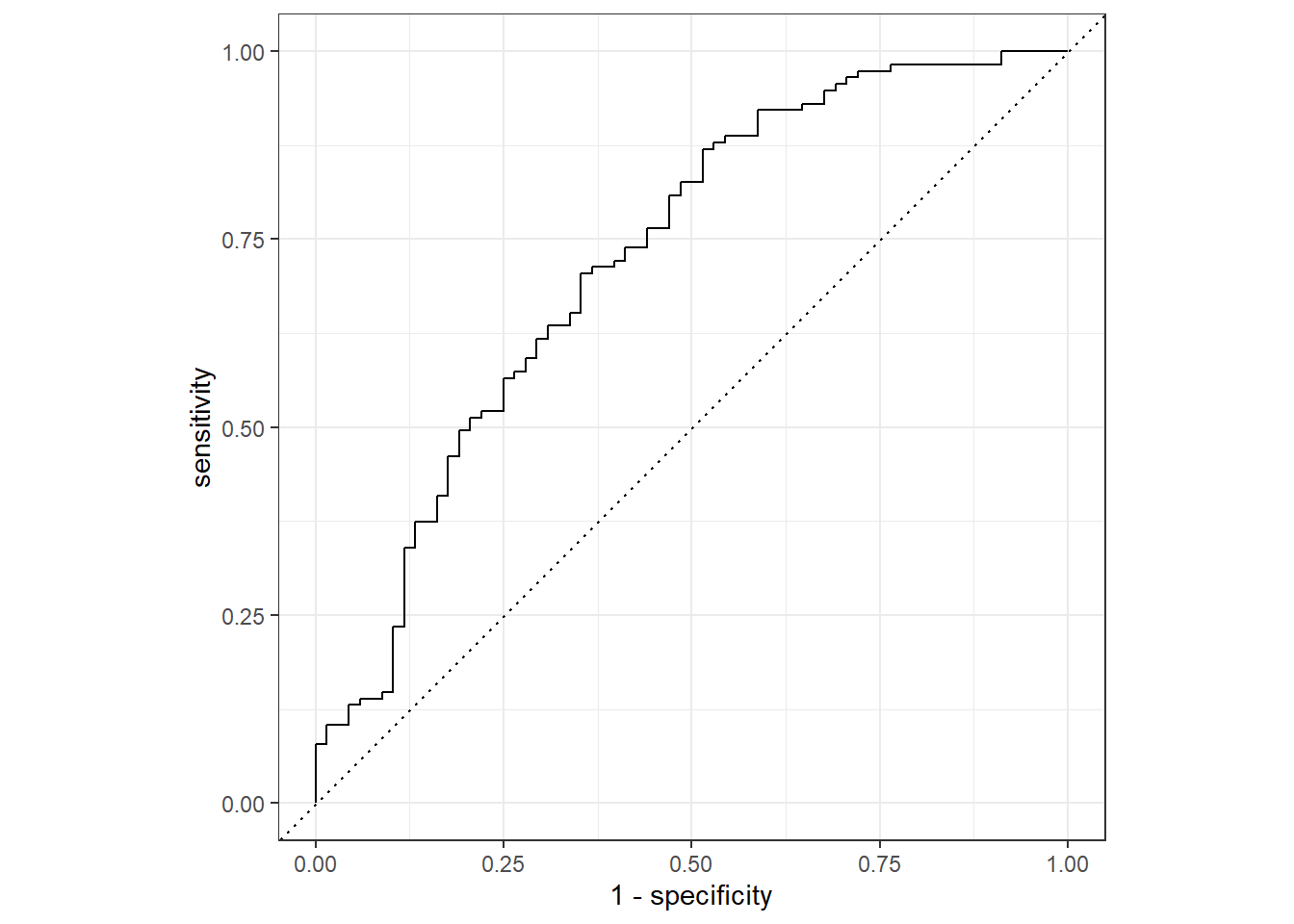
#Use roc_curve to evaluate modelflu_aug %>%roc_curve(truth = Nausea, .pred_No) %>%autoplot()
#Use roc_aug to quantify area under roc-curveflu_aug %>%roc_auc(truth = Nausea, .pred_No)
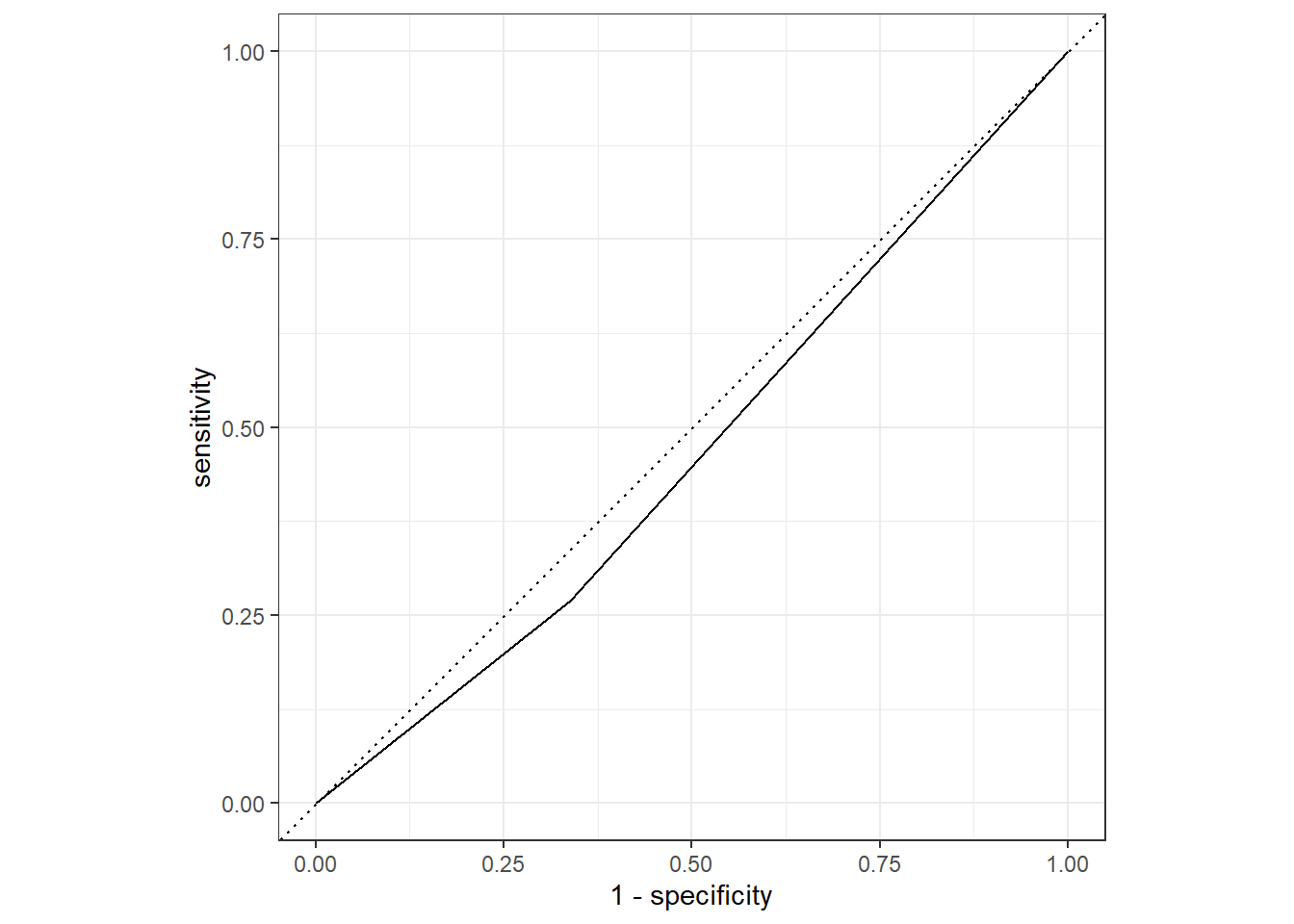
#Augment to return probabilities rather than yes or noflu_runnynose_aug <-augment(flu_runnynose_fit, test_data)#Use roc_curve to evaluate modelflu_runnynose_aug %>%roc_curve(truth = Nausea, .pred_No) %>%autoplot()
#Use roc_aug to quantify area under roc-curveflu_runnynose_aug %>%roc_auc(truth = Nausea, .pred_No)
Since the ROC is estimated to be 0.466, it is not a well performing model according to this metric.
Kelly Hatfield’s Additions
Model with all predictors
#create the recipe and workflowflu_rec_lin <-recipe(BodyTemp ~ ., data = train_data) #model specificationlin_mod <-linear_reg() %>%set_engine("lm")#workflowflu_wflow_lin <-workflow() %>%add_model(lin_mod) %>%add_recipe(flu_rec_lin)flu_wflow_lin
══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: linear_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
0 Recipe Steps
── Model ───────────────────────────────────────────────────────────────────────
Linear Regression Model Specification (regression)
Computational engine: lm
#create the fit from the established workflowflu_fit_lin <- flu_wflow_lin %>%fit(data = train_data)#check prediction to evaluate test datapredict(flu_fit_lin, test_data)
Warning in predict.lm(object = object$fit, newdata = new_data, type =
"response"): prediction from a rank-deficient fit may be misleading
# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 1.15
We see that the training data performed a bit better with our RMSE estimated to be 1.11 versus with the tested data at 1.15, but similar results
Model with 1 predictor
#create the recipe and workflowflu_rec_lin <-recipe(BodyTemp ~ RunnyNose, data = train_data) #model specificationlin_mod <-linear_reg() %>%set_engine("lm")#workflowflu_wflow_lin <-workflow() %>%add_model(lin_mod) %>%add_recipe(flu_rec_lin)flu_wflow_lin
══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: linear_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
0 Recipe Steps
── Model ───────────────────────────────────────────────────────────────────────
Linear Regression Model Specification (regression)
Computational engine: lm
#create the fit from the established workflowflu_fit_lin <- flu_wflow_lin %>%fit(data = train_data)#check prediction to evaluate test datapredict(flu_fit_lin, test_data)